참고:
https://www.youtube.com/watch?v=aX9c7z9l_u8
https://velog.io/@dhldksgehl/%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98%EC%9D%98-%EA%B2%A9%EB%A6%AC%EC%88%98%EC%A4%80
⏳ 트랜잭션을 정의해보자
트랜잭션이란?
데이터 베이스의 상태를 변화시키기 위해 수행하는 작업 단위로 쪼갤 수 없는 업무 처리의 최소 단위를 말합니다.
모든 DBMS는 자체적으로 트랜잭션을 지원하는데 이러한 트랜잭션을 관리하기 위한 설정을 가지고 있습니다.

⏳ DBMS는 어떻게 반영될까?
DBMS는 명령을 끝마칠 때까지 수행내역을 로그에 저장해둡니다.

**
Operation 컬럼**
행위를 나타내는 Operation 칼럼을 간략하게 보면 아래와 같습니다.
이 정도가 있다 정도로만 알아보고 넘어가겠습니다.

DBMS는 반영된 내용을 재반영하기 위한 redo log와 수행을 실패해 이전의 상태로 되돌리는 undo log를 이용해 트랜잭션을 지원합니다. 하지만 이렇게 DBMS에서 보장해주는 하나의 명령이 아닌 여러명령을 하나의 트랜잭션으로 묶는것을 예시로 알아보겠습니다.
유리바를 운영하는 곳에 철수와 훈이가 N빵을 하는 과정을 예시로 들어보자.
1. 훈이가 유리바에서 술을 먹었다.

2. 훈이는 유리에게 10,000원을 카카오페이로 송금하려고 한다.
훈이는 유리에게 송금 버튼을 누른다.
3. 훈이가 송금버튼을 누르면 훈이계좌에 10,000 이상의 금액이 존재하는지 확인해야 한다.
4. 훈이의 계좌에는 10,000원이 존재하므로 훈이의 계좌에서 10,000원을 차감하고
유리의 계좌에 10,000원을 더해야 한다.
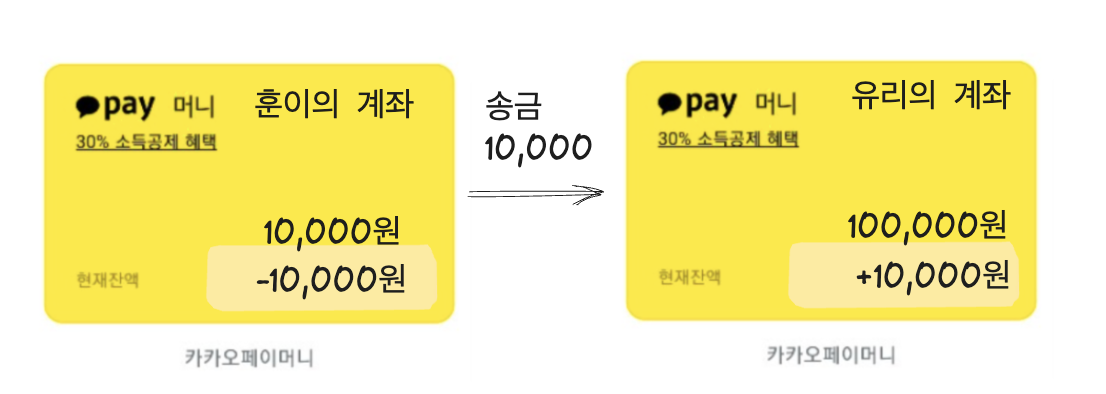
이러한 일련의 작업은 절대로 분리되어서는 안되고 일부만 실행되어서도 안됩니다.
이러한 절대로 깨져서는 안되는 하나의 작업을 트랜잭션이라고 합니다.
이러한 트랜잭션은 4가지 성질을 바탕으로 신뢰를 보장합니다.
이를 무결성이라고 합니다.
⏳ 무결성이란?
데이터 무결성은 데이터의 정확성, 일관성, 유효성이 유지되는 것을 의미합니다.
정확성은 중복이나 누락이 없는 상태를 뜻하고,
일관성은 원인과 결과의 의미가 연속적으로 보장되어 변하지 않는 상태를 뜻합니다.
유효성은 데이터가 올바른 값으로 들어왔는지를 뜻합니다.
만약 데이터베이스에서 데이터 무결설 설계를 하지 않는다면 테이블에 중복된 데이터 존재, 부모와 자식 데이터 간의 논리적 관계 깨짐, 잦은 에러와 재개발 비용 발생 등과 같은 여러 문제가 발생할 것입니다.
⏳ 트랜잭션의 무결성을 보장하는 4가지 성질 ACID
⏳원자성(Atomicity)
만약 훈이가 돈을 보내는것까지 실행되었는데 카카오톡(데이터센터가 날아간다던가) DB에 어떠한 장애가 발생하여
유리의 계좌에 돈이 증가하지 않았다면 유리는 훈이를 용서하지 못 할테고 토끼 신세가 될 수 있습니다.

이렇듯! 트랜잭션은 절대 깨지지 않은 원자처럼 하나가 전부 실행되든지,
전부 실패 해야지 일부만 실행되는 경우는 없다는 원자성을 지닙니다.
이러한 트랜잭션 종료를 위해 롤백이나 커밋이 수행 되어야 합니다.
롤백(Rollback) - DCL(TCL)
여러 명령을 실행시에 어느 하나라도 실패했다면 이전에 성공한 훈이가 돈을 보내는것 까지의 동작을 없었던 일처럼 되돌리는 것을 롤백이라고 합니다.
커밋(Commit) - DCL(TCL)
훈이가 유리에게 돈을 보내고 유리계좌에 성공적으로 입금이 되었다면 수정된 모든 내용을 데이터베이스에 반영합니다.
⏳일관성(Consistency)
데이터베이스의 상태, 데이터베이스 내의 계층 관계, 컬럼의 속성 등이 항상 일관되게 유지되어야 한다는 일관성이 있습니다.
예를 들어, 훈이가(트랜잭션) 돈을 보내기 전과 송금이 끝난 후에 계좌의 총 잔액은 변하지 않아야 합니다.
중간 단계에서 어떠한 오류 또는 문제가 발생하더라도 데이터베이스는 일관된 상태를 유지해야 함을 말합니다.
⏳지속성(Durability)
트랜잭션이 성공적으로 수행되어 커밋 되었다면 어떠한 문제가 발생하더라도 데이터베이스에 그 내용이 영원히 지속되어야한다.
이를 위해 모든 트랜잭션은 로그로 남겨져 어떠한 장애에도 대비할 수 있도록 한다.
⏳독립성(Isolation)
트랜잭션 수행 시 다른 트랜잭션이 작업에 끼어들 수 없고 각 트랜잭션을 독립적으로 수행해야 한다는 독립성이 있습니다.
예를 들어, 훈이와 철수가 유리에게 10,000원을 동시에 송금한다고 가정해보겠습니다.
순차적으로 진행될 경우 기존 10만원에서 유리계좌의 잔액은 12만원이 되어야 하지만,
분명히 송금했음에도 불구하고 최종 잔액이 11만원인 문제가 발생할 수 있습니다.

트랜잭션은 격리 수준 설정을 통한 독립성 보장으로 이러한 경우를 방지하고 있습니다.
(격리 수준 설정의 경우 좀 더 아래에서 다뤄보도록 하겠습니다.)
하지만 데이터베이스에 작업이 들어왔을 때,
모든 작성의 독립성을 보장해 하나씩 순차적으로 진행하게 된다면,
CPU는 DBMS보다 아웃풋 작업을 빈번히 수행하기 때문에 트랜잭션을 순차적으로 수행하면
CPU는 점점 응답을 기다리는 시간이 길어져 프로그램이 비 효율적으로 동작하는 문제가 발생할 수 있습니다.
결국..
서비스에 따라서 성능을 챙길것 인지, 무결성을 챙길것 인지에 대한 트레이드 오프를 고려해보고 설계해보아야겠습니다.
⏳ 격리 수준 설정(Isolation Level)
독립성에서 다루었던 격리 수준 설정은 여러 사용자가 동일한 데이터를 동시에(훈이와 철수의 송금) 수정하려고 할 때,
데이터베이스에서 제공하는 기능중 하나가 격리수준인데 트랜잭션끼리 얼마나 서로 고립되어 있는지를 나타내는 수준입니다.
과한 무결성을 챙기는것은 위에서 언급했던 CPU의 응답시간이 길어지는 결과를 초래합니다.
데이터베이스는 locking을 제공하는데 동시에 수행되는 수많은 트랜잭션을 격리 수준을 통해 조절할 수 있습니다.
레벨이 높아질수록 트랜잭션간 고립정도가 높아지며, Locking을 강하게하면 성능이 낮아지지만 무결성을 보장합니다.
반대로 Locking을 느슨하게 한다면 데이터의 무결성에 큰 문제를 가져옵니다.
효율적인 Locking의 사용을 위해 적절한 격리수준은 반드시 필요합니다.

Dirty Read -> 다른 세션에서 커밋되지 않은 데이터를 읽을 수 있는 현상
Non Repeatable Read -> 다른 세션에서 커밋(UPDATE)된 데이터를 읽음으로써 조회(select) 할 떄마다 결과값이 달라지는 현상
Phantom Read -> 다른 세션에서 커밋(Insert, Delete)된 데이터를 읽음으로써 쿼리 결과가 달라지는 현상
Non Repeatable Read와 Phantom Read의 차이점은 값과 쿼리 결과입니다.
값은 하나의 row에 의한 열값을 의미합니다.
쿼리 결과는 여러 쿼리들의 모음을 의미합니다.
Non Repeatable Read는 한 로우가 가지고 있는 컬럼을 의미합니다.
Phantom Read는 여러 로우에 해당하며 updated 뿐 아니라 insert, delete 쿼리로 sum, count와 같이 결과가 달라지는 현상을 포함합니다.
⏳Read Uncommitted(Level 0)
어떤 트랜잭션의 내용이 커밋(Commit)이나 롤백(Rollback)과 상관없이 다른 트랜잭션에서 조회가 가능합니다.
문제가 많은 격리 수준이기 때문에 RDBMS 표준에서는 격리수준으로 인정하지 않습니다.
Select문이 실행되는 동안 해당 Data에 Shared Lock이 걸리지 않아 Dirty Read가 발생합니다.
한 트랜잭션이 변경 중인 데이터에 대한 다른 트랜잭션의 변경 내용을 볼 수 있습니다.
즉, 훈이의 계좌이체가 진행 되던 도중 성공하지 못 했을 경우에도,
도중에 조회한 훈이의 계좌는 0원이 찍힌다고 볼 수 있습니다.
⏳Read Committed(Level 1)
이 격리 수준에서는 커밋된 데이터만 읽을 수 있습니다.
다른 트랜잭션에서 변경 중인 데이터는 볼 수 없습니다. 이로 인해 Dirty Read는 발생하지 않지만,
Non-Repeatable Read(부정합) 문제가 발생할 수 있습니다.
오라클에서 기본적으로 사용되고 있으며 온라인 서비스에서 가장 많이 선택되는 격리 수준입니다.
예로 두개의 트랜잭션이 동시에 실행된다고 가정 해보겠습니다.
1. 두 명의 관리자가 주문 처리 시스템을 사용하여 주문을 확인합니다.
2. A가 주문을 확인하고 주문상태를 "처리 중"으로 표시합니다.
3. B가 동일한 주문을 확인하고 주문 상태가 "처리 중"인지 확인합니다.
4. 이때! A 가 주문을 처리하고 주문 상태를 "완료"로 변경하게 됩니다.
5. B는 같은 주문을 다시 확인해보니 "완료"로 나타나게 되어 일관성이 꺠지게 됩니다.
이와 같은 문제는 데이터의 일관성과 정확성이 정확하지 않을 수 있으며 불일치 문제가 발생할 수 있습니다.
⏳Repeatable Read(Level 2)
트랜잭션이 시작되기 전에 커밋된 내용에 대해서만 조회가 가능합니다.
이 격리 수준에서는 Non Repeatable Read가 발생하지 않습니다.
트랜잭션이 완료될 때까지 Select문이 사용하는 모든 데이터에 Shared Lac이 걸립니다.
따라서 트랜잭션이 범위 내에서 조회한 데이터의 내용이 항상 동일함을 보장합니다.
트랜잭션이 시작 시점 데이터의 일관성을 보장해야 하기 때문에 트랜잭션의 실행시간이 길어질수록 계속 멀티버전을 관리해야하 는 단점이 발생합니다. 하지만 Phantom Read가 발생할 수 있습니다.
⏳SERIALIZABLE(Level 3)
가장 단순하면서 엄격한 격리 수준이지만 성능측면에서 동시 처리성능이 가장 낮습니다.
Phantom Read가 발생하지 않고 트랜잭션들이 순차적으로 실행되는 것처럼 동작합니다만 거의 사용되지 않습니다.

⏳ 마치며
DBMS에 따라서 격리 수준도 다르고 각 수준의 동작 방식도 상이하지만 큰틀에서는 같다고 볼 수 있습니다.
격리 수준을 적절하게 제어해서 완성된 서비스를 만드는것이 중요하다고 느꼈습니다.
관계형 데이터베이스 관리 시스템에서 사용되는 InnoDB엔진 등 공부할게 너무 많다고 생각이들며
다음 포스팅으론 Lock에 대해서 좀 더 심도있게 파보거나 Web파트쪽을 좀 더 다룰예정입니다.
긴글 읽어주셔서 감사합니다 피드백이나 잘못알고 있는점이 있다면 거침없이 피드백 부탁드립니다!

'CS > DB' 카테고리의 다른 글
| SQL JOIN (0) | 2023.10.15 |
|---|---|
| 서브쿼리(Subquery)란 (0) | 2023.10.15 |
| DB, DBMS, SQL에 대해 알아보자 (0) | 2023.09.12 |
